












基于预训练模型和高分辨网络的蒙古语多模态情感分析方法-9479威尼斯
更新时间:2024-08-09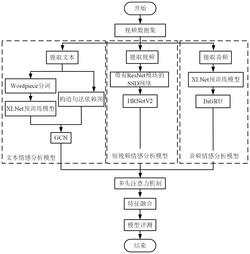 专利申请类型:发明专利;
专利申请类型:发明专利;源自:内蒙古高价值专利检索信息库;
专利名称:基于预训练模型和高分辨网络的蒙古语多模态情感分析方法
专利类型:发明专利
专利申请号:cn202310586171.6
专利申请(专利权)人:内蒙古工业大学
权利人地址:内蒙古自治区呼和浩特市土默特左旗内蒙古工业大学金川校区
专利发明(设计)人:仁庆道尔吉,赫瑞凤,吉亚图,刘娜,石宝
专利摘要:一种基于预训练模型和高分辨网络的蒙古语多模态情感分析方法,对含有文本、短视频和音频的中文视频数据集进行机器翻译,得到蒙古语多模态情感语料,使用xlnet预训练模型和gcn提取文本情感特征,使用残差ssd网络和高分辨率表示网络hrnet提取视频情感特征,使用双向门控网络bigru提取音频情感特征;引入多头注意力机制,动态调整权重信息,将提取的特征作为最终的情感特征;采用softmax函数对最终的情感特征进行分类,得到最终的分类结果。本发明能够克服由于蒙古语语料短缺带来情感分析不准确问题,并进一步提升对蒙古语的分析和舆情预测能力。
主权利要求:
1.一种基于预训练模型和高分辨网络的蒙古语多模态情感分析方法,其特征在于,包括如下步骤:步骤1:对含有文本、短视频和音频的中文视频数据集进行机器翻译,得到蒙古语多模态情感语料;所述短视频中包含人脸,所述音频中包含人类语音;
步骤2:对蒙古语多模态情感语料中的蒙古语文本,利用文本情感分析模型提取文本情感特征;所述文本情感分析模型,使用wordpiece分词技术将文本编码为单词向量,然后使用xlnet预训练模型和gcn提取文本情感特征;
步骤3:对蒙古语多模态情感语料中的蒙古语短视频,利用视频情感分析模型提取视频情感特征;所述视频情感分析模型,使用残差ssd网络和高分辨率表示网络hrnet提取视频情感特征;
步骤4:对蒙古语多模态情感语料中的蒙古语音频,利用音频情感分析模型提取音频情感特征;所述音频情感分析模型使用双向门控网络bigru提取音频情感特征;
步骤5:引入多头注意力机制,动态调整所述文本情感特征、所述视频情感特征和所述音频情感特征的权重,得到最终的情感特征;
步骤6:采用softmax函数对最终的情感特征进行分类,得到最终的分类结果。
2.根据权利要求1所述基于预训练模型和高分辨网络的蒙古语多模态情感分析方法,其特征在于,所述步骤1,将含有文本、音频和短视频的中文视频数据集进行提取得到文本、短视频和音频一一对应的数据,并通过神经机器翻译和人工校正处理,得到文本、短视频和音频一一对应的蒙古语多模态情感语料。
3.根据权利要求1所述基于预训练模型和高分辨网络的蒙古语多模态情感分析方法,其特征在于,所述步骤2,对蒙古语文本进行语料预处理后,先使用wordpiece分词技术,提取词的索引和词向量,建立索引字典和向量字典,转换为数组;然后以所述数组为xlnet预训练模型的输入,提取特征向量sxlnet;对蒙古语文本,若句子中的某个词与其他词存在依存关系,则赋值为1;若不存在依存关系,则赋值为0,得到一个稀疏的邻接矩阵a,利用g={v,e}表示基于邻接矩阵a所构建的句法依赖图,v表示一个句子中节点的集合;e表示词和词之间依存关系的集合;将sxlnet和邻接矩阵a共同作为图卷积神经网络gcn的输入,所得的输出即为文本情感特征ft。
4.根据权利要求3所述基于预训练模型和高分辨网络的蒙古语多模态情感分析方法,其特征在于,在gcn中,对使用注意力机制所得的特征向量sxlnet和邻接矩阵a进行卷积,得zi,即文本情感特征ft:其中relu代表激活函数;a为依赖句法关系构建的邻接矩阵; 为a的度矩阵,wc为gcn中的权重矩阵。
5.根据权利要求1所述基于预训练模型和高分辨网络的蒙古语多模态情感分析方法,其特征在于,所述步骤3,对蒙古语短视频,首先基于残差ssd网络获取视频局部时空情感特征,再通过hrnet对其进行建模实现面部关键点检测,从而得到二维时空情感特征,接着在二维时空情感特征的基础上利用卷积神经网络再次学习深层特征得视频情感特征fv。
6.根据权利要求5所述基于预训练模型和高分辨网络的蒙古语多模态情感分析方法,其特征在于,所述hrnet为hrnetv2,通过双线性上采样重新调整低分辨率表示,而不改变高分辨率的通道数量,并连接四个表示,然后进行1×1卷积以混合四个表示;将由残差ssd网络初步提取的局部时空情感特征作为hrnet的输入,不断融合不同尺度的信息得最终的视觉情感特征fv。
7.根据权利要求1所述基于预训练模型和高分辨网络的蒙古语多模态情感分析方法,其特征在于,所述步骤4,对蒙古语音频,首先使用opensmile提取低级语音特征,将其中的梅尔频率倒谱系数作为音频情感分析模型的输入;
然后基于xlnet将提取出的梅尔频率倒谱系数编码为固定长度的离散序列作为bigru的输入;
最后使用bigru提取音频情感特征fa。
8.根据权利要求1所述基于预训练模型和高分辨网络的蒙古语多模态情感分析方法,其特征在于,所述步骤5,根据文本情感特征ft、音频情感特征fa和视觉情感特征fv,学习av特征矩阵fab、at特征矩阵fat和vt特征矩阵fvt,如下所示:其中,vt表示视觉‑文本,at表示声学‑文本,av表示声学‑视觉, 表示点积运算;ft={t1,t2,…,tn},fa={a1,a2,…,an},fv={v1,v2,…,vn},n为样本数量;tn、an、vn分别表示第n个文本情感特征、第n个音频情感特征和第n个视频情感特征;
使用relu激活函数作用于fav、fat和fvt,变换后的特征如下所示:其中wav、wat、wvt为可学习的变换矩阵,bav、bat、bvt为偏置矩阵;
将 和 输入到共享层以减少存储空间,得到模态间相互作用特征hs,如下所示:
其中s∈{av,at,vt},fc为全连通层,θ为可学习参数矩阵;
将提取的模态间相互作用特征进行拼接,如下:
d=concat(hav,hat,hvt)
d表示多模态特征,包括多种模态的所有特征,concat表示拼接;
对d、hav、hat、hvt进行多头线性投影,并映射到具有相同维数dm的空间,如下:其中wd1,wd2为多模态特征d的不同的投影矩阵,wq为av、at、vt的投影矩阵,i为不同投影空间中运算的指标,对不同的双峰特征使用相同的参数矩阵av、at、vt注意力机制应用如下:
其中 为采用不同投影矩阵对多模态特征d进行投影运算后的投影矩阵,
为对不同的双峰特征使用相同的参数矩阵 的运算结果;
将每个头部的av、at和vt注意分别进行级联并进行线性层变换,如下:其中,wo为权重参数矩阵,h为投影空间指标。 说明书 : 基于预训练模型和高分辨网络的蒙古语多模态情感分析方法技术领域[0001] 本发明属于人工智能技术领域,涉及自然语言处理,特别涉及一种基于预训练模型和高分辨网络的蒙古语多模态情感分析方法。背景技术[0002] 随着互联网技术的迅速发展,网络已经成为了人们传播和发布各种信息、发表各种想法的主要手段。网络用户产生的数据林林总总各式各样,包括文字、音频、视频等多种数据形式。用户在各种平台记录、分享,传达着她们的情绪,[0003] 这些信息、想法的发布或多或少都带有用户的个人情感倾向,有着大量的情绪信息。多模态信息给用户带来更多的感官效果,用户随之发布的信息也提供了宝贵的蕴含情绪信息的资源。[0004] 随着人工智能的崛起,深度学习方法得到了广泛的关注,因其模型具有强大的特征学习能力,所以逐渐成为了解决情感分类问题的重要方法。但对于蒙古语这样的小语种来说,现有的情感分析方法存在以下三点不足。其一,由于蒙古语词汇丰富形态变化多,就造成了在蒙古语文本情感分析过程中出现了严重的未登录词现象,而大量未登录词的存在严重影响情感分析的准确率。其二,深度学习作为一种数据驱动的方法,只有当训练语料库达到一定的要求,深度学习模型才会表现出较好的分析效果。但可以收集到的蒙古语语料资源相对较少,因此无法满足深度神经网络模型训练的要求。其三,传统的神经网络模型在解决情感分析时分类效率有限,而由于蒙古语语料短缺等原因,目前预训练模型并没有在蒙古语情感分析领域得到充分的研究。发明内容[0005] 为了克服上述现有技术的缺点,本发明的目的在于提供一种基于预训练模型和高分辨网络的蒙古语多模态情感分析方法,以期克服由于蒙古语语料短缺带来情感分析不准确问题,并进一步提升对蒙古语的分析和舆情预测能力。[0006] 为了实现上述目的,本发明采用的技术方案是:[0007] 一种基于预训练模型和高分辨网络的蒙古语多模态情感分析方法,包括如下步骤:[0008] 步骤1:对含有文本、短视频和音频的中文视频数据集进行机器翻译,得到蒙古语多模态情感语料;所述短视频中包含人脸,所述音频中包含人类语音;[0009] 步骤2:对蒙古语多模态情感语料中的蒙古语文本,利用文本情感分析模型提取文本情感特征;所述文本情感分析模型,使用wordpiece分词技术将文本编码为单词向量,然后使用xlnet预训练模型和gcn提取文本情感特征;[0010] 步骤3:对蒙古语多模态情感语料中的蒙古语短视频,利用视频情感分析模型提取视频情感特征;所述视频情感分析模型,使用残差ssd网络和高分辨率表示网络hrnet提取视频情感特征;[0011] 步骤4:对蒙古语多模态情感语料中的蒙古语音频,利用音频情感分析模型提取音频情感特征;所述音频情感分析模型使用双向门控网络bigru提取音频情感特征;[0012] 步骤5:引入多头注意力机制,动态调整所述文本情感特征、所述视频情感特征和所述音频情感特征的权重,得到最终的情感特征;[0013] 步骤6:采用softmax函数对最终的情感特征进行分类,得到最终的分类结果。[0014] 在一个实施例中,所述步骤1,将含有文本、音频和短视频的中文视频数据集进行提取得到文本、短视频和音频一一对应的数据,并通过神经机器翻译和人工校正处理,得到文本、短视频和音频一一对应的蒙古语多模态情感语料。[0015] 在一个实施例中,所述步骤2,对蒙古语文本进行语料预处理后,先使用wordpiece分词技术,提取词的索引和词向量,建立索引字典和向量字典,转换为数组;然后以所述数组为xlnet预训练模型的输入,提取特征向量sxlnet;对蒙古语文本,若句子中的某个词与其他词存在依存关系,则赋值为1;若不存在依存关系,则赋值为0,得到一个稀疏的邻接矩阵a,利用g={v,e}表示基于邻接矩阵a所构建的句法依赖图,v表示一个句子中节点的集合;e表示词和词之间依存关系的集合;将sxlnet和邻接矩阵a共同作为图卷积神经网络gcn的输入,所得的输出即为文本情感特征ft。[0016] 与现有技术相比,本发明的有益效果是:[0017] (1)对含有文本、视觉和音频的中文视频数据集进行神经机器翻译和人工校正处理,得到蒙古语多模态情感语料。本发明采用wordpiece分词技术以及蒙古语情感词典修正方法结合,更好的缓解因蒙古语语法的复杂性而出现的未登录词问题。[0018] (2)本发明通过采用xlnet和gcn、残差ssd网络和hrnet、bigru分别学习蒙古语文本、短视频和音频三种模态的情感特征。从全方位、深层次、多角度进行情感分析。[0019] (3)本发明通过使用多头注意力机制调整文字情感特征、视觉情感特征和音频情感特征的权重,获得更丰富的情感特征,提高情感分析模型的可信度和精确性。附图说明[0020] 图1是本发明基于预训练模型和高分辨率网络的蒙古语多模态情感分析方法的流程图。[0021] 图2是xlnet结构示意图。[0022] 图3是基于预训练模型的蒙古语文本情感分析模型示意图。[0023] 图4是残差块示意图。[0024] 图5是残差ssd网络示意图。[0025] 图6是连接来自所有分辨率的(上采样)表示的hrnetv2模型示意图。[0026] 图7是短视频情感特征提取流程图。[0027] 图8是gru隐藏状态结构图。[0028] 图9是gru结构图。[0029] 图10是基于bigru的音频情感分析模型示意图。[0030] 图11是基于多头注意力机制的蒙古语多模态情感特征融合模型。[0031] 图12是本发明实施例在10个训练周期中的准确率变化趋势。具体实施方式[0032] 下面结合附图和实施例详细说明本发明的实施方式。[0033] 如图1所示,本发明一种基于预训练模型和高分辨网络的蒙古语多模态情感分析方法,过程如下:[0034] 步骤1:对含有文本、短视频和音频的中文视频数据集进行机器翻译,得到蒙古语多模态情感语料。其中短视频中一般应包括人脸,音频中则应包括人类语音。[0035] 由于蒙古语多模态情感语料信息不足,本发明对含有文本、短视频和音频的中文视频数据集进行提取得到文本、短视频和音频一一对应的数据,并通过神经机器翻译和人工校正处理,得到文本、短视频和音频一一对应的蒙古语多模态情感语料,达到扩充蒙古语语料的目的。示例地,短视频可采用gif格式,占用空间小。[0036] 步骤2:对蒙古语多模态情感语料中的蒙古语文本,利用文本情感分析模型提取文本情感特征。所述文本情感分析模型,使用wordpiece分词技术将文本编码为单词向量,然后使用xlnet预训练模型和gcn提取文本情感特征。[0037] 具体地,在本步骤中:[0038] 首先,对语料进行预处理,然后使用wordpiece分词技术训练数据,提取词的索引和词向量,建立索引字典和向量字典,转换为数组,作为xlnet预训练模型的输入。[0039] 其次,利用xlnet预训练模型提取特征向量sxlnet。[0040] 考虑到在标注数据很少的情况下,通过神经网络训练出的模型往往精度有限,而预训练可以很好地解决这个问题,并能对一词多义进行建模。因此基于xlnet构建蒙古语的预训练模型。xlnet是卡内基梅隆大学和谷歌研究人员在2019年开发的,应用置换语言建模目标来整合自回归(ar)和自动编码(ae)语言建模的优势,通过在输入序列分解顺序的所有排列上最大化期望似然,预先训练以学习双向上下文。在xlnet模型中,所有的记号都是随机预测的。参考图2,基于xlnet的特征提取以位置和特征极性为输入,输出为特征向量,过程可描述如下:[0041] 1)使用wordpiece词汇表为预处理阶段的每个输出词设置预定义的词id。[0042] 2)将特殊标记放在序列的开始[cls]和结束[sep]处[0043] 3)将每个标记转换为向量表示[0044] 4)计算其输入的位置编码,见式(1‑1)和(1‑2)[0045][0046][0047] 5)由公式(1‑3)计算自注意力[0048][0049] 其中wq为查询矩阵,wk为键矩阵,wv为值矩阵,dk为键向量的维度,softmax为用于将得分归一化为概率值的函数。[0050] 6)在通过单层的感知之前将多注意总结为一个自注意[0051] 7)基于排列在目标词之前的词来预测目标词,见式(1‑4),其中xlnet允许从所有位置收集更多信息。[0052][0053] 8)使用编码标记的输出[cls],将编码输出设置为类别,在这些类别下,所有值均由公式(1‑5)中所示的概率分布确定:[0054] p(n|emb)=f(ct·mc)(1‑5)[0055] 其中ct是前馈激活函数,mc是用于将函数映射到n个类的矩阵。[0056] 句法也是自然语言处理中的基础性工作,它分析句子的句法结构(主谓宾结构)和词汇间的依存关系(并列,从属等)。随着深度学习在nlp中的使用,句法分析已经变得不是非常必要。但是,蒙古语句法结构复杂,且标注样本较少,句法分析仍可以发挥出很大的作用。因此研究句法分析依然是很有必要的。本发明将xlnet和gcn结合,使模型能够利用句子的句法结构信息。kpif等提出句子中的每个词与其本身相邻接,即邻接矩阵中的对角线元素均赋值为1。[0057] 对本发明的蒙古语文本,基于依存句法树中的依存关系,若句子中的某个词与其他词存在依存关系,则赋值为1。若不存在依存关系,则赋值为0,得到一个稀疏的邻接矩阵a。利用g={v,e}表示基于邻接矩阵a所构建的句法依赖图,v表示一个句子中节点的集合。e表示词和词之间依存关系的集合。将sxlnet和邻接矩阵a共同作为图卷积神经网络gcn的输入,gcn对使用注意力机制所得的特征表示sxlnet和邻接矩阵a进行卷积,得zi,即文本情感特征ft:[0058][0059] 其中relu代表激活函数;a为依赖句法关系构建的邻接矩阵; 为a的度矩阵,wc为gcn中的权重矩阵。[0060] 本发明采用集成模型的思想,将xlnet预训练模型提取的特征sxlnet和根据文本构造的句法分析图得到的稀疏的邻接矩阵共同作为图卷积神经网络gcn的输入,所得的输出作为模型最终提取的文本情感特征ft,模型可参考图3所示。[0061] 本步骤中,针对蒙古语文本特征,采用分词技术对数据进行分词,使用预训练模型提取出的特征和根据文本构造的句法分析图所提取的邻接矩阵共同输入图卷积神经网络中进行融合,能更好地缓解因蒙古语语法的复杂性而出现的未登录词问题,以提高蒙古语文本情感分析的质量。[0062] 步骤3:对蒙古语多模态情感语料中的蒙古语短视频,利用视频情感分析模型提取视频情感特征。所述视频情感分析模型,使用残差ssd网络和高分辨率表示网络hrnet提取视频情感特征。[0063] 参考图4和图5,本步骤中,对蒙古语短视频,首先基于残差ssd网络获取视频局部时空情感特征,再通过语义上更丰富,空间上更精确的hrnet对其进行建模实现面部关键点检测,从而得到二维时空情感特征,接着在二维时空情感特征的基础上利用卷积神经网络再次学习深层特征得视频情感特征fv。[0064] 残差网络是许多残差块堆积到一起之后形成一种较深的网络结构。残差块可以用来跳过对模型精度提升效果欠佳的层的训练。在ssd算法中采用resnet作为基础网络,既具有加深神经网络层数提升模型效果,且对其它数据集泛化能力较强的作用,又可以允许网络更深,使得模型更小但又具有较强的表征能力。之后将产生的输出经过处理作为高分辨率表示网络hrnet的输入。hrnet并行连接高到低卷积流。它在整个过程中保持高分辨率表示,从第一阶段的高分辨率子网开始,从高分辨率到低分辨率依次添加子网,形成多个阶段,将多分辨率子网并行连接,并在整个过程中重复交换并行多分辨率子网中的信息,进行重复的多尺度融合来生成具有强位置敏感性的可靠高分辨率表示。[0065] 示例地,hrnet使用hrnetv2,参考图6,通过双线性上采样重新调整低分辨率表示,而不改变高分辨率的通道数量,并连接四个表示,然后进行1×1卷积以混合四个表示。将由残差ssd网络初步提取的局部时空情感特征作为hrnet的输入,不断融合不同尺度的信息得最终的视觉情感特征fv,过程可参考图7。[0066] 本步骤中,将提取短期局部时空情感特征的残差ssd网络和提取高分辨率表示的hrnet网络融合,以提高蒙古语短视频情感分析的质量。[0067] 步骤4:对蒙古语多模态情感语料中的蒙古语音频,利用音频情感分析模型提取音频情感特征。所述音频情感分析模型使用双向门控网络bigru提取音频情感特征。[0068] 语音情感分析任务中的音频片段处理是一个序列任务。音频信号不仅具有复杂的空间特征,而且具有丰富的时间特征。音频信号的顺序对模型分析其情感特征非常重要。语音情感分析通过采集说话人的语音信号,并对原始信号预处理后再进行特征提取与分类,为减弱采集信号时由于声音采集设备差异引入的噪声等,需对语音信号进行提高语音高频部分的预加重、切割较长的语音信号为固定长度的分帧等预处理操作。在语音信号分帧后,每一帧的起始位置和终止位置都会出现间断,切分的帧数越多,与原始信号之间的误差值越大。[0069] 对蒙古语音频,本发明首先使用opensmile提取低级语音特征。这些特征包括12个梅尔频率倒谱系数(mfccs,mel‑scalefrequencycepstralcoefficients)、音调跟踪、浊音/浊音分割特征、声门源参数和峰值斜率参数。一般来说,梅尔频率倒谱系数是原始音频的准确表示。mfcc即梅尔频率倒谱系数,是音频的时域信号经过fft变换成频谱,再映射在梅尔频率上,再经过idft变换过程中的0‑l个系数(l通常取12‑16)。因此本发明使用梅尔频率倒谱系数作为音频情感分析模型的输入。[0070] 然后,基于xlnet将提取出的梅尔频率倒谱系数编码为固定长度的离散序列作为bigru的输入。由于多模态特征融合需要对数据进行矩阵操作,以确保与文本特征长度相同,故音频特征的不满所需步长的部分缺失部分设为0。[0071] 最后使用双向门控网络(bigru,bidirectionalgaterecurrentunit)提取合适的音频情感特征fa,用于后续模态融合。[0072] 参考图8和图9,gru(gatedrecurrentunit)是一种特殊循环神经网络(rnn),由两个循环神经网络(rnn)组成,充当编码器和解码器对。编码器将变长源序列映射到定长向量,解码器将向量表示映射回变长目标序列。在给定源序列的情况下,两个网络联合训练以最大化目标序列的条件概率。为了解决标准rnn的梯度消失问题,gru使用了更新门(updategate)与重置门(resetgate)。基本上,这两个门控向量决定了哪些信息最终能作为门控循环单元的输出。这两个门控机制的特殊之处在于,它们能够保存长期序列中的信息,且不会随时间而清除或因为与预测不相关而移除。[0073] gru中重置门rt的计算方法如下:[0074] ri=σ([wrx]j [urh<t‑1>]j)(1‑7)[0075] 类似地,更新门zj由下式计算:[0076] zi=σ([wzx]j [uzh<t‑1>]j)(1‑8)[0077] 隐藏状态计算公式为:[0078][0079] 其中,[0080][0081] 在这个公式中,当复位门接近0时,隐藏状态被强制忽略之前的隐藏状态,并使用当前输入重置。这有效地允许隐藏状态删除将来发现不相关的任何信息,从而允许更紧凑的表示。[0082] 由于每个隐藏单元都有单独的重置和更新门,每个隐藏单元将学习在不同的时间尺度上捕获依赖关系。那些学会捕获短期依赖关系的单元将倾向于具有频繁活动的重置门,但那些捕获长期依赖关系的单元将具有大部分活动的更新门。将基于bigru的音频情感分析模型得到的输出作为音频情感特征fa,过程可参考图10所示。[0083] 本步骤中,基于bigru能够提取蒙古语音频复杂的空间特征和丰富的时间特征。[0084] 步骤5:引入多头注意力机制,动态调整所述文本情感特征、所述视频情感特征和所述音频情感特征的权重,得到最终的情感特征;[0085] 网络中的情感数据复杂多样,各模态情感特征的贡献程度对最后的情感分类会产生直接的影响。为了反映不同情感特征向量的重要性,本发明拟在特征融合层采用跨模态分层融合的方式捕捉对话语境中最有效的词汇,从而获得更准确的情感语义向量表示。参考图11,以文本情感特征ft、音频情感特征fa和视觉情感特征fv作为输入。对于多模态交互,本发明使用外积表示视觉‑文本(vt)、声学‑文本(at)和声学‑视觉(av)特征。[0086] ft={t1,t2,…,tn},fa={a1,a2,…,an},fv={v1,v2,…,vn},n[0087] 为样本数量。tn、an、vn分别表示第n个文本情感特征、第n个音频情感特征和第n个视频情感特征。任意两个模态的张量融合是外积。根据ft、fa和fv可以学习av特征矩阵fav、at特征矩阵fat和vt特征矩阵fvt,如式(1‑11)所示。[0088][0089] 其中,vt表示视觉‑文本,at表示声学‑文本,av表示声学‑视觉, 表示点积运算。[0090] 为了获得维数一致的特征,使用relu激活函数作用于fav、fat和fvt,变换后的特征如式(1‑12)所示。其中wav、wat、wvt为可学习的变换矩阵,bav、bat、bvt为偏置矩阵。[0091][0092] 为了进一步提取深层特征,将 和 输入到共享层以减少存储空间,共享层意味着用于训练这三个成对特征的参数是共享的。如式(1‑13)所示,得到模态间相互作用特征,表示为hs,其中s∈{av,at,vt},fc为全连通层,θ为可学习参数矩阵。[0093][0094] 为了进行模态间信息交互,计算成对模态的贡献,并从不同表示子空间中捕获相关信息,将提取的跨模态相互作用特征进行拼接,如式(1‑14)所示。d表示多模态特征,包括多种模态的所有特征,concat表示拼接。[0095] d=concat(hav,hat,hvt)(1‑14)[0096] 对特征矩阵d、hav、hat、hvt进行多头线性投影,并映射到具有相同维数dm的空间,如下式(1‑15)所示。[0097][0098] 其中wd1,wd2为多模态特征d的不同的投影矩阵,wq为av、at、vt的投影矩阵,i为不同投影空间中运算的指标,对不同的双峰特征使用相同的参数矩阵 以减少参数数量和内存消耗。在获得不同投影空间的特征后,利用注意机制探索成对模态之间的互补关系。av、at、vt注意力机制应用如下式所示:[0099][0100] 其中 为采用不同投影矩阵对多模态特征d进行投影运算后的投影矩阵, 为对不同的双峰特征使用相同的参数矩阵 的运算结果。[0101] 为了得到分配注意后的成对模态间特征表示,将每个头部的av、at和vt注意分别进行级联并进行线性层变换。如式(1‑17)所示,wo为权重参数。[0102][0103] 其中,wo为权重参数,h为投影空间指标。[0104] 综上,将基于xlnet的蒙古语文本情感分析模型和短视频情感分析网络模型做并行处理,采用跨模态特征融合的方式动态分配文本情感特征、视频情感特征和音频情感特征的权重得到最终的情感特征。将此多模态特征融合模型作为最终的蒙古语多模态情感分析模型。[0105] 本步骤采用多头注意力机制从不同层面考虑相关性,给予注意力层的输出包含有不同子空间中的编码表示信息,从而增强模型的表达能力。[0106] 步骤6:采用softmax函数对最终的情感特征进行分类,得到最终的分类结果。[0107] 步骤7:将基于预训练模型和高分辨表示的蒙古语多模态情感分析模型的分析结果单独的文本情感分析模型、短视频情感分析模型和音频情感分析模型的分析结果就准确率、精确率、召回率和f1值进行对比和评价,以达到提高蒙古语多模态情感分析和舆情预测性能的目的。[0108] 具体地,准确率的计算公式 精确率的计算公式为召回率的计算公式为 f1值的计算公式为 其中acc表示准确率,p表示精确率,r表示召回率,f1表示f1值,tp表示实际为正例,且被模型预测为正例的样本数量。fn表示被模型预测为负例,但实际上为正例的样本数量。fp表示被模型预测为正例,但实际上为负例的样本数量。tn表示实际为负例,且被模型预测为负例的样本数,所述准确率、精确率、召回率和f1值的分数越高说明情感分析模型性能越好。[0109] 如表1所示,给出了计算中所需的混淆矩阵。[0110] 表2混淆矩阵表[0111] 预测为正例 预测为负例实际为正例 tp fn预测为负例 fp tn[0112] 案例1:为证明本发明所提方法的有效性,针对中文视频数据集进行提取并通过神经机器翻译和人工校正处理得到的蒙古语文本情感语料做了以下实验。[0113] 文本情感语料数据集中包含积极、消极两个情感类别,共1836条数据。实验选用每个类别数据的80%作为训练集,剩余的20%作为测试集。首先,对每条数据进行数据清洗并删除无关数据,其次,采用分词方式对数据进行分词处理并转换成词向量,每个词向量维度是768。然后,利用本发明所提的文本情感分析模型对该数据集信息进行情感分类。最后,在分类准确率指标上评价。在10个训练周期中的准确率变化趋势如图12所示。可以看出分类准确率由上图可以看出,本发明所提的文本情感分析模型能够在较短的训练周期内情感分类准确率就能够达到大于0.7的效果。以上实验能够充分证明本发明所提方法的有效性,该方法能够为蒙古文情感分析任务提供理论及实践参考。
专利地区:内蒙古
专利申请日期:2023-05-23
专利公开日期:2024-07-09
专利公告号:cn116738359b
以上信息来自国家知识产权局,如信息有误请联系我方更正!


