












一种异构粒度存储系统中的缺失率曲线构建方法和系统-9479威尼斯
更新时间:2024-08-01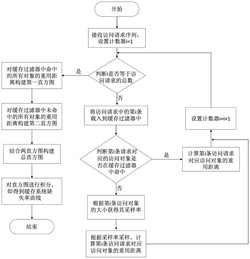 专利申请类型:发明专利;
专利申请类型:发明专利;地区:湖北-武汉;
源自:武汉高价值专利检索信息库;
专利名称:一种异构粒度存储系统中的缺失率曲线构建方法和系统
专利类型:发明专利
专利申请号:cn202210789994.4
专利申请(专利权)人:华中科技大学
权利人地址:湖北省武汉市洪山区珞喻路1037号华中科技大学
专利发明(设计)人:郭潇俊,王桦,周可,韩耀东,谭頔凡
专利摘要:本发明公开了一种异构粒度存储系统中的缺失率曲线构建方法,包括:接收访问请求序列,并设置计数器i=1,判断i是否等于访问请求序列中的访问请求总数,如果不等于则将访问请求序列中的第i条访问请求载入缓存过滤器中,并判断该第i条访问请求对应的访问对象是否在缓存过滤器中命中,如果没有则根据第i条访问请求对应的访问对象的大小获取该访问对象的采样率,根据得到的第i条访问请求对应的访问对象的采样率对该访问对象进行采样,并计算该访问对象的重用距离,设置计数器i=i 1。本发明能够解决现有异构粒度存储系统中由于内容流行度差异以及对象大小差异,从而导致的字节缺失率曲线与对象缺失率曲线构建不准确的技术问题。
主权利要求:
1.一种异构粒度存储系统中的缺失率曲线构建方法,其特征在于,包括以下步骤:(1)接收访问请求序列,并设置计数器i=1;
(2)判断i是否等于访问请求序列中的访问请求总数,如果是则进入步骤(8),否则转入步骤(3);
(3)将访问请求序列中的第i条访问请求载入缓存过滤器中,并判断该第i条访问请求对应的访问对象是否在缓存过滤器中命中,如果是则转入步骤(4),否则转入步骤(5);
(4)获取该第i条访问请求对应的访问对象的重用距离,然后转入步骤(7);
(5)根据第i条访问请求对应的访问对象的大小获取该访问对象的采样率;
(6)根据步骤(5)得到的第i条访问请求对应的访问对象的采样率对该访问对象进行采样,并计算该访问对象的重用距离,然后转入步骤(7);
(7)设置计数器i=i 1,并返回步骤(2);
(8)根据访问请求队列中所有在缓存过滤器中命中的访问对象的重用距离构建第一直方图,然后转入步骤(9);
(9)根据访问请求队列中所有未在缓存过滤器中命中的访问对象的重用距离构建第二直方图,然后转入步骤(10);
(10)合并第一直方图与第二直方图,构建完整的重用距离直方图,并对重用距离直方图进行积分处理,以获得最终的缺失率曲线。
2.根据权利要求1所述的异构粒度存储系统中的缺失率曲线构建方法,其特征在于,步骤(1)是从缓存系统中获取的实际运行的访问请求序列。
3.根据权利要求1或2所述的异构粒度存储系统中的缺失率曲线构建方法,其特征在于,每条访问请求仅对应一个访问对象,一个访问对象对应至少一条访问请求。
4.根据权利要求3所述的异构粒度存储系统中的缺失率曲线构建方法,其特征在于,缓存过滤器中仅保留最近的大小不大于l的访问对象,其中l的取值范围是0到5×1/r×log2(1/r),其中r为预设的基础采样率大小。
5.根据权利要求4所述的异构粒度存储系统中的缺失率曲线构建方法,其特征在于,访问对象i的重用距离为该访问对象i在距上一次被访问的间隔之内除了该访问对象之外的其余所有访问对象的大小之和;
访问对象d的采样率rd是按照以下公式计算得到:
rd=r×sd/savg
其中sd为访问对象的大小,savg为访问请求序列中所有访问请求对应的访问对象的平均值。
6.根据权利要求5所述的异构粒度存储系统中的缺失率曲线构建方法,其特征在于,步骤(6)包括以下子步骤:(6‑1)根据步骤(5)中计算得到的第i条访问请求对应的访问对象的采样率rd对第i条访问请求对应的访问对象进行采样,以生成一个0到1的随机数,并判断该随机数是否小于等于rd,如果是则转入步骤(6‑2),否则过程结束;
(6‑2)构建二叉树tws,使得二叉树tws的中序遍历等价于步骤(5)得到的第i条访问请求对应的访问对象的先后顺序;
(6‑3)根据步骤(6‑2)得到的二叉树tws计算第i条访问请求对应的访问对象的重用距离sbrd;
(6‑4)使用步骤(6‑3)得到的第i条访问请求对应的访问对象的重用距离并根据公式ebrd=sbrd/r size(tcf)获取第i条访问请求对应的访问对象的最终重用距离ebrd,其中size(tcf)是缓存过滤器中存储的所有访问对象的总大小。
7.根据权利要求6所述的异构粒度存储系统中的缺失率曲线构建方法,其特征在于,在第一直方图中,横坐标1表示的是重用距离,其对应的纵坐标,是重用距离为1的访问对象的总数;
在第二直方图中,横坐标1表示的是重用距离,其对应的纵坐标,是重用距离为1的访问对象的总数。
8.一种异构粒度存储系统中的缺失率曲线构建系统,其特征在于,包括:第一模块,用于接收访问请求序列,并设置计数器i=1;
第二模块,用于判断i是否等于访问请求序列中的访问请求总数,如果是则进入第八模块,否则转入第三模块;
第三模块,用于将访问请求序列中的第i条访问请求载入缓存过滤器中,并判断该第i条访问请求对应的访问对象是否在缓存过滤器中命中,如果是则转入第四模块,否则转入第五模块;
第四模块,用于获取该第i条访问请求对应的访问对象的重用距离,然后转入第七模块;
第五模块,用于根据第i条访问请求对应的访问对象的大小获取该访问对象的采样率;
第六模块,用于根据第五模块得到的第i条访问请求对应的访问对象的采样率对该访问对象进行采样,并计算该访问对象的重用距离,然后转入第七模块;
第七模块,用于设置计数器i=i 1,并返回第二模块;
第八模块,用于根据访问请求队列中所有在缓存过滤器中命中的访问对象的重用距离构建第一直方图,然后转入第九模块;
第九模块,用于根据访问请求队列中所有未在缓存过滤器中命中的访问对象的重用距离构建第二直方图,然后转入第十模块;
第十模块,用于合并第一直方图与第二直方图,以构建完整的重用距离直方图,并对重用距离直方图进行积分处理,以获得最终的缺失率曲线。 说明书 : 一种异构粒度存储系统中的缺失率曲线构建方法和系统技术领域[0001] 本发明属于计算机数据存储领域,更具体地,涉及一种异构粒度存储系统中的缺失率曲线构建方法和系统。背景技术[0002] 对象级缓存是网络中非常常见的缓存技术,其主要评价指标有字节缺失率(bytemissingrate,简称bmr)和对象缺失率(objectmissingrate,简称omr)两种。在网络缓存中,字节丢失率可以直接反映带宽开销和缓存提供商的流量开销,因此其应用非常重要。更好的缓存策略可以在给定的缓存大小上获得更低的丢失率,并且,更好的缓存资源管理可以提高共享缓存的所有应用程序的总体性能。缺失率曲线(missratecurve,简称mrc)是一种定量的缓存性能建模技术,其构建的方法在缓存资源管理中起着至关重要的作用。[0003] 针对mrc的构建方法在过去得到了广泛的研究,其构建方法主要有:准确的mrc构建方法、近似的mrc构建方法、基于空间哈希采样的mrc构建方法等。准确的mrc构建方法通过逐对象计算重用距离,可以得到较为精确的构建结果;近似的mrc构建通过近似和等效的处理方法,使得计算开销较小,且误差在可容忍范围之内;基于空间哈希采样的mrc构建方法通过哈希采样技术,能以较低的计算开销在异构粒度存储系统中实现mrc的构建。[0004] 然而,现有的mrc构建方法在异构粒度存储系统的运用中存在者一些问题:第一、若要实现mrc的准确构建,必然伴随着极高的时间和空间复杂度,导致计算开销很大;第二、在异构粒度存储系统缓存(如对象存储)中,对象尺寸的差异会带来mrc的构建误差,以及字节缺失率曲线(bytemissingratecurve,简称bmrc)与对象缺失率曲线(objectmissingratecurve,简称omrc)之间存在较大的构建误差;第三、不同对象的不同内容流行程度(即请求概率)会导致前端mrc构建不准确,从而影响mrc的整体准确性。发明内容[0005] 针对现有技术的以上缺陷或改进需求,本发明提供了一种异构粒度存储系统中的缺失率曲线构建方法,其目的在于,解决现有mrc构建方法在实现mrc的准确构建期间,必然伴随着极高的时间和空间复杂度,从而导致计算开销很大的技术问题,以及在异构粒度存储系统缓存(如对象存储)中,对象尺寸的差异会带来mrc的构建误差,以及bmrc与omrc之间存在较大的构建误差的技术问题,以及不同对象的不同内容流行程度会导致前端mrc构建不准确,从而影响mrc整体准确性的技术问题。[0006] 为实现上述目的,按照本发明的一个方面,提供了一种用于缺失率曲线构建的采样方法,包括以下步骤:[0007] (1)接收访问请求序列,并设置计数器i=1;[0008] (2)判断i是否等于访问请求序列中的访问请求总数,如果是则进入步骤(8),否则转入步骤(3);[0009] (3)将访问请求序列中的第i条访问请求载入缓存过滤器中,并判断该第i条访问请求对应的访问对象是否在缓存过滤器中命中,如果是则转入步骤(4),否则转入步骤(5);[0010] (4)获取该第i条访问请求对应的访问对象的重用距离,然后转入步骤(7);[0011] (5)根据第i条访问请求对应的访问对象的大小获取该访问对象的采样率;[0012] (6)根据步骤(5)得到的第i条访问请求对应的访问对象的采样率对该访问对象进行采样,并计算该访问对象的重用距离,然后转入步骤(7);[0013] (7)设置计数器i=i 1,并返回步骤(2);[0014] (8)根据访问请求队列中所有在缓存过滤器中命中的访问对象的重用距离构建第一直方图,然后转入步骤(9)。[0015] (9)根据访问请求队列中所有未在缓存过滤器中命中的访问对象的重用距离构建第二直方图,然后转入步骤(10);[0016] (10)合并第一直方图与第二直方图,构建完整的重用距离直方图,并对重用距离直方图进行积分处理,以获得最终的缺失率曲线。[0017] 优选地,步骤(1)是从缓存系统中获取的实际运行的访问请求序列。[0018] 优选地,每条访问请求仅对应一个访问对象,一个访问对象对应至少一条访问请求。[0019] 优选地,缓存过滤器中仅保留最近的大小不大于l的访问对象,其中l的取值范围是0到5×1/r×log2(1/r),优选为1/r×log2(1/r),其中r为预设的基础采样率大小。[0020] 优选地,访问对象i的重用距离为该访问对象i在距上一次被访问的间隔之内除了该访问对象之外的其余所有访问对象的大小之和;[0021] 访问对象d的采样率rd是按照以下公式计算得到:[0022] rd=r×sd/savg[0023] 其中sd为访问对象的大小,savg为访问请求序列中所有访问请求对应的访问对象的平均值;[0024] 优选地,步骤(6)包括以下子步骤:[0025] (6‑1)根据步骤(5)中计算得到的第i条访问请求对应的访问对象的采样率rd对第i条访问请求对应的访问对象进行采样,以生成一个0到1的随机数,并判断该随机数是否小于等于rd,如果是则转入步骤(6‑2),否则过程结束;[0026] (6‑2)构建二叉树tws,使得二叉树tws的中序遍历等价于步骤(5)得到的第i条访问请求对应的访问对象的先后顺序;[0027] (6‑3)根据步骤(6‑2)得到的二叉树tws计算第i条访问请求对应的访问对象的重用距离sbrd;[0028] (6‑4)使用步骤(6‑3)得到的第i条访问请求对应的访问对象的重用距离并根据公式ebrd=sbrd/r size(tcf)获取第i条访问请求对应的访问对象的最终重用距离ebrd,其中size(tcf)是缓存过滤器中存储的所有访问对象的总大小。[0029] 优选地,在第一直方图中,横坐标1表示的是重用距离,其对应的纵坐标,是重用距离为1的访问对象的总数。[0030] 在第二直方图中,横坐标1表示的是重用距离,其对应的纵坐标,是重用距离为1的访问对象的总数。[0031] 按照本发明的另一方面,提供了一种异构粒度存储系统中的缺失率曲线构建系统,包括:[0032] 第一模块,用于接收访问请求序列,并设置计数器i=1;[0033] 第二模块,用于判断i是否等于访问请求序列中的访问请求总数,如果是则进入第八模块,否则转入第三模块;[0034] 第三模块,用于将访问请求序列中的第i条访问请求载入缓存过滤器中,并判断该第i条访问请求对应的访问对象是否在缓存过滤器中命中,如果是则转入第四模块,否则转入第五模块;[0035] 第四模块,用于获取该第i条访问请求对应的访问对象的重用距离,然后转入第七模块;[0036] 第五模块,用于根据第i条访问请求对应的访问对象的大小获取该访问对象的采样率;[0037] 第六模块,用于根据第五模块得到的第i条访问请求对应的访问对象的采样率对该访问对象进行采样,并计算该访问对象的重用距离,然后转入第七模块;[0038] 第七模块,用于设置计数器i=i 1,并返回第二模块;[0039] 第八模块,用于根据访问请求队列中所有在缓存过滤器中命中的访问对象的重用距离构建第一直方图,然后转入第九模块。[0040] 第九模块,用于根据访问请求队列中所有未在缓存过滤器中命中的访问对象的重用距离构建第二直方图,然后转入第十模块;[0041] 第十模块,用于合并第一直方图与第二直方图,以构建完整的重用距离直方图,并对重用距离直方图进行积分处理,以获得最终的缺失率曲线。[0042] 总体而言,通过本发明所构思的以上技术方案与现有技术相比,能够取得下列有益效果:[0043] 1、由于本发明采用了步骤(5)到步骤(6),应用了采样的计算方式,能够降低时间与空间复杂度,从而降低mrc曲线构建的计算开销;此外,由于采用了步骤(3)到步骤(6),分开考虑缺失率曲线的头部和尾部的构建问题,在降低开销的同时保证了准确性满足要求。[0044] 2、由于本发明采用了步骤(5)到步骤(6),对不同尺寸的对象采取不同的采样率进行变权重采样的处理,能够避免对象大小差异造成的缺失率曲线构建不准确问题,降低bmrc与omrc之间存在的构建误差,大大提高了缓存缺失率曲线构建的准确率。[0045] 3、由于本发明采用了步骤(3)到步骤(4),将内容流行度高的对象单独计算其重用距离,分开考虑缺失率曲线的头部和尾部的构建问题,提高了高内容流行度对象的重用距离统计精度,大大提高了mrc曲线的头部构建精度。[0046] 4、本发明作为通用性的工具,很容易在内容发布网络、网页缓存等其他应用场景灵活迁移适用,可以帮助缓存系统实现更灵活、更高效的多目标缓存优化。附图说明[0047] 图1是本发明异构粒度存储系统中的缺失率曲线构建方法的流程图在所有附图中,相同的附图标记用来表示相同的元件或结构。具体实施方式[0048] 为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。[0049] 如图1所示,本发明提供了一种异构粒度存储系统中的缺失率曲线构建方法,其主要包含两个部分:缓存过滤器以及变权重采样阶段,两部分分别用于构建缺失率曲线的头部和尾部,以提高缺失率曲线的构建精度。[0050] 具体而言,本发明异构粒度存储系统中的缺失率曲线构建方法包括以下步骤:[0051] (1)接收访问请求序列,并设置计数器i=1;[0052] 具体而言,本步骤是从缓存系统中获取的实际运行的访问请求序列记录。[0053] (2)判断i是否等于访问请求序列中的访问请求总数,如果是则进入步骤(8),否则转入步骤(3);[0054] (3)将访问请求序列中的第i条访问请求载入缓存过滤器中,并判断该第i条访问请求对应的访问对象是否在缓存过滤器中命中,如果是则转入步骤(4),否则转入步骤(5);[0055] 具体而言,每条访问请求仅仅对应一个访问对象,一个访问对象可以对应多条访问请求。[0056] 缓存过滤器使用二叉树tcf来构建访问请求序列,使得二叉树的中序遍历等价于访问请求序列访问对象的先后顺序,以快速计算访问请求序列对应的访问对象的重用距离。并且,缓存过滤器中仅保留最近的大小不大于l的访问对象,其中l的取值范围是0到5×1/r×log2(1/r),优选为1/r×log2(1/r),其中r为预设的基础采样率大小,可以在0到1之间任意选择,与步骤(5)中的基础采样率大小相同。[0057] (4)获取该第i条访问请求对应的访问对象的重用距离,然后转入步骤(7);[0058] 具体而言,访问对象i的重用距离为,访问对象i在距上一次被访问的间隔之内除了该访问对象之外的其余所有访问对象的大小之和。[0059] 上述步骤(3)到(4)的优点在于,对内容流行度高的对象单独计算重用距离,后续对其构建准确的重用距离直方图,可以提高缺失率曲线在头部的准确率,从而整体提高缺失率曲线的准确程度。[0060] (5)根据第i条访问请求对应的访问对象的大小获取该访问对象的采样率;[0061] 具体而言,访问对象d的采样率rd是按照以下公式计算得到:[0062] rd=r×sd/savg[0063] 其中sd为访问对象的大小,savg为访问请求序列中所有访问请求对应的访问对象的平均值;[0064] (6)根据步骤(5)得到的第i条访问请求对应的访问对象的采样率对该访问对象进行采样,并计算该访问对象的重用距离,然后转入步骤(7);[0065] 具体而言,重用距离的计算策略是:[0066] (6‑1)根据步骤(5)中计算得到的第i条访问请求对应的访问对象的采样率rd对第i条访问请求对应的访问对象进行采样,以生成一个0到1的随机数,并判断该随机数是否小于等于rd,如果是则转入步骤(6‑2),否则过程结束;[0067] (6‑2)构建二叉树tws,使得二叉树tws的中序遍历等价于步骤(5)得到的第i条访问请求对应的访问对象的先后顺序;[0068] (6‑3)根据步骤(6‑2)得到的二叉树tws计算第i条访问请求对应的访问对象的重用距离sbrd;[0069] 具体而言,本步骤中的计算方法与步骤(4)中完全相同,在此不再赘述。[0070] (6‑4)使用步骤(6‑3)得到的第i条访问请求对应的访问对象的重用距离并根据公式ebrd=sbrd/r size(tcf)获取第i条访问请求对应的访问对象的最终重用距离ebrd,其中size(tcf)是缓存过滤器中存储的所有访问对象的总大小。[0071] 上述步骤(6‑1)到(6‑4)的优点在于,对不同大小的对象采用不同的抽样率,减少了随机采样的方差,进一步降低了缺失率曲线在尾部的误差,降低了对象尺寸差异对mrc构建的影响,从而提高整体缺失率曲线的准确程度。[0072] (7)设置计数器i=i 1,并返回步骤(2);[0073] (8)根据访问请求队列中所有在缓存过滤器中命中的访问对象的重用距离构建第一直方图,然后转入步骤(9);[0074] 具体而言,在第一直方图中,横坐标1表示的是重用距离,其对应的纵坐标,是重用距离为1的访问对象的总数。[0075] (9)根据访问请求队列中所有未在缓存过滤器中命中的访问对象的重用距离构建第二直方图,然后转入步骤(10);[0076] 具体而言,在第二直方图中,横坐标1表示的是重用距离,其对应的纵坐标,是重用距离为1的访问对象的总数。[0077] (10)合并第一直方图与第二直方图,以构建完整的重用距离直方图,并对重用距离直方图进行积分处理,以获得最终的缺失率曲线。[0078] 从缺失率曲线的工作流程可以看出,相较于传统的构建流程,本发明増加了缓存过滤器,使得内容流行度高的对象单独计算,从而减少了传统采样计算造成的缺失率曲线头部误差大的问题。此外,本发明在传统采样的基础上,根据对象的大小对不同对象采用不同的采样率,减少了对象大小差异对缺失率曲线构建准确度的影响。[0079] 本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
专利地区:湖北
专利申请日期:2022-07-05
专利公开日期:2024-07-09
专利公告号:cn115130032b
以上信息来自国家知识产权局,如信息有误请联系我方更正!


